- Published on
How Artifex Leveraged ChatGPT to Analyze Text Data for an Open-Source Acquisition
Note: This is a real case study from a 2023 consulting project with Artifex. Specific numbers and prompts are omitted due to an NDA.
Unstructured Data contains higher quality signals
Most data analysis focuses on numbers. They're easy to aggregate, slice, and visualize. In contrast, unstructured data like text, images, and audio is often relegated to specialized ML tasks like sentiment analysis or named-entity recognition (NER). We rarely see it integrated into mainstream BI dashboards because it’s messy and hard to quantify. This is quite a missed opportunity. Other modalities data in general and textual data, in particular, contains rich context and intent that numbers alone can't capture. Passive numeric data collection mostly captures how users interact with your app or software but textual data often contains why are users acting a certain way. The good news is that with modern LLMs, we no longer need to treat text as an impenetrable data type. While a fully integrated, multi-modal analysis platform is probably still a few years away at least, we can solve high-value, specific problems today. This is the story of one such problem: extracting product usage intent from raw sales inquiries. Analysis of unstructured sales queries Artifex directly led them to acquire an open-source project, demonstrating a clear ROI on analyzing "messy" text.
From Vague Sales Inquiries to Actionable Insights
In mid-2023, I was working at Artifex (The company creates and maintains a lot of PDF related technologies) as data analyst and was given a broad directive: find insights in the free-text sales queries submitted through their contact form. These inquiries were a mix of licensing questions and detailed project descriptions from technical users. The goal was to understand users' needs better. The data was a classic unstructured text problem. The submission form had changed over years, so there was no consistent structure. Users misspelled product names, used different terms for the same technology, and described complex use cases. Here are a few anonymized examples of the raw data:
- Example 1: "We are developing an internal microservice and API in our AWS environment which will handle PDF to TIFF conversion... A notification will be sent to a Typescript/Javascript x86 based Lambda Function, which will then call into a private Lambda Layer... which will trigger a shell script to perform the conversion..."
- Example 2: "Hi Support team... I'm from Japan. I'm developing a product and I want to use GhostScript for install php-imagick of PHP. I just wan to use php-imagick but installing needs GhostScript. Can you show me price for my case."
- Example 3: "Hello, I'm an independent C# developer and I'm considering using XAML->XPS->PDF conversion for some of my desktop apps for my client(s). It would be used to print short PDF reports... I simply need to know the ballpark pricing you have for GhostXPS." A simple keyword search or NER wouldn't work. A lot of details are implicit and requires understanding semantic relationships between the entities mentioned either directly or implicitly like humans but automatically which brings us to .... ChatGPT!
A Systematic Approach to Prompt Engineering
The initial idea was to use ChatGPT's API to extract a structured summary from each query such as useacse mentioned, identifying or inferring the product name(s) by usecase, Operating System, programming language and framework but the first attempts with simple, zero-shot prompts yielded messy, inconsistent results. The model struggled to produce clean JSON and often hallucinated or misattributed relationships. So, it was pretty clear that "just prompting" wouldn't work and it needed a more rigorous, iterative process described below:
Define a Success Metric: I defined a correct extraction as one where all key entities (product, use case, tech stack) were accurately identified and linked. The primary metric was the ratio of correct extractions to total queries
Statistical Sampling: Manually verifying thousands of outputs was impractical—the very problem I was trying to solve with an LLM. Instead, I framed it as a statistical estimation problem. I calculated the sample size needed to estimate the success metric with a high confidence interval.
Iterative Prompt Refinement Loop: For each new prompt version, I would:
- Run the extraction pipeline on the entire dataset.
- Draw a random sample of the outputs.
- Manually review the sample, counting correct vs. incorrect extractions. (This process could not be reliably automated. can you guess why?)
- Critically, I also categorized the types of errors the LLM was making (e.g., confusing two products, failing to abstract a use case). This error analysis directly informed the modifications for the next prompt iteration.
Manual Post-Processing: After several iterations, I achieved a high accuracy rate. The final step was a manual post-processing pass to standardize the extracted entities. For example, "PDF -> JPEG conversion" and "JPEG to PDF" were both mapped to a single "Format Conversion" category. This step, while manual, was now manageable because the LLM had done 90% of the heavy lifting. After this step, this is how the data looked like:
| Query | UseCase | language | OS | Product |
|---|---|---|---|---|
| We are developing an internal microservice and API in our AWS environment which will handle PDF to TIFF conversion... A notification will be sent to a Typescript/Javascript x86 based Lambda Function, which will call into a private Lambda Layer... which will trigger a shell script to perform the conversion... | PDF conversion | Shell | Linux | GhostScript |
| Hi Support team... I'm from Japan. I'm developing a product which ... I need to use GhostScript to install php-imagick. Can you show me price for my case? | PDF conversion | PHP | Linux | GhostScript |
| We want to add MuPDF in our app as PDF Viewer | PDF Rendering | MuPDF |
(Sometimes information could not be inferred or extracted as shown in third query)
Outcome
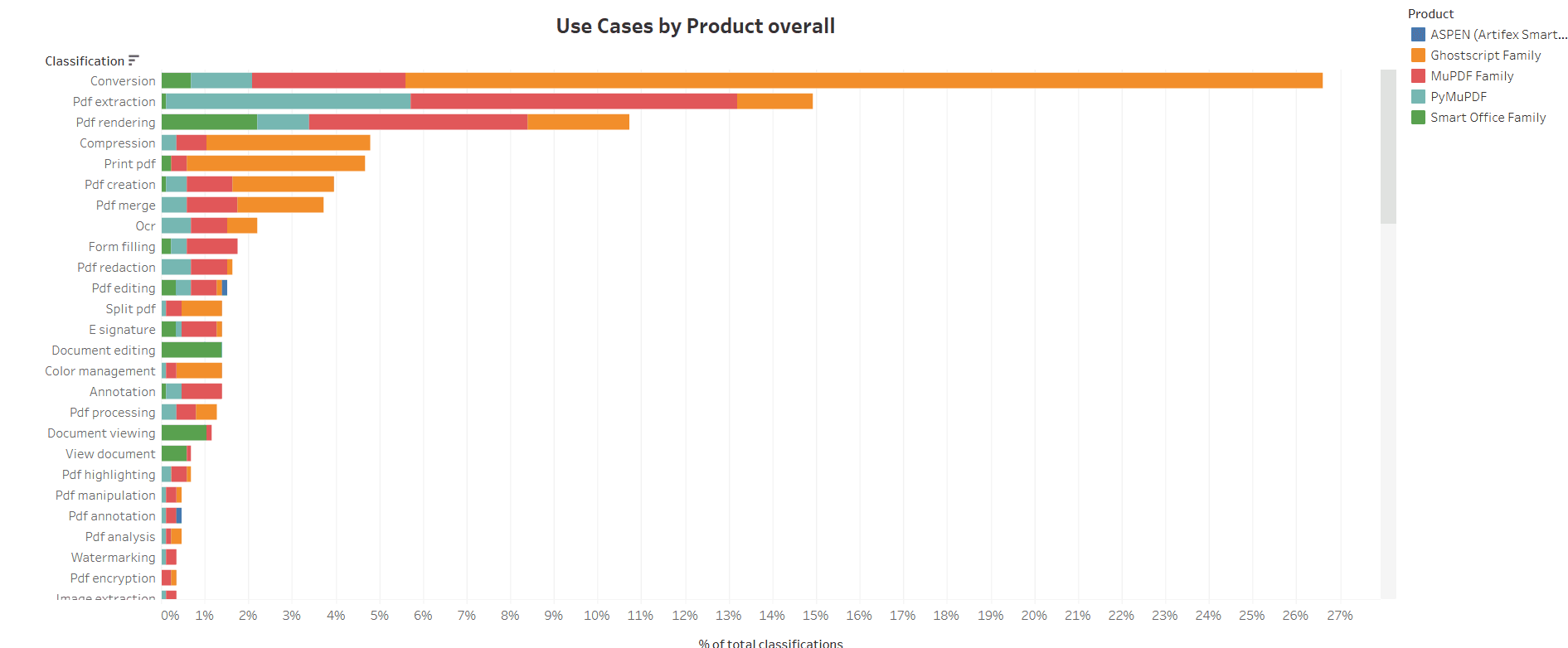
The chart revealed several patterns, but one stood out immediately: Conversions between different file formats was the most popular usecase with GhostScript. Upon segmenting GhostScript queries by language and OS, it was found that most commercial users were using it on Windows with C#. This was a non-obvious insight. While the company knew Ghostscript was popular, the strong affinity within the .NET ecosystem was a surprise. This data provided a clear signal of an underserved market segment. With this insight, Artifex identified Ghostscript.NET, the most popular .NET binding for Ghostscript, as a strategic asset. Within 45 days, Artifex acquired the repository from its owner. The acquisition allowed them to improve the user experience for a key demographic, create better product synergy, and overhaul the documentation to address the most common use cases.
Start Analyzing Your Text
Could this analysis have been done without an LLM? Yes, but it would have required weeks of tedious manual categorization, likely making the project prohibitively expensive and slow. The LLM reduced the effort by at least an order of magnitude. Since I completed this project in 2023, the technology has only improved:
Structured Output: Modern models have much more reliable structured data generation (like JSON mode), reducing the need for post-processing.
Cost & Performance: Smaller, efficient open-source models can now handle parts of this workflow, lowering costs.
Advanced Techniques: The rise of embeddings and Retrieval-Augmented Generation (RAG) unlocks even more powerful ways to query and analyze text corpora.
The barrier to extracting value from unstructured data has been dramatically lowered. Analysts no longer need to be ML engineers to tackle these problems. By combining clever prompting, a systematic validation process, and classic data analysis, we can surface game-changing insights that are invisible in spreadsheets so If you're sitting on a pile of customer emails, support tickets, product reviews etc - Just start analyzing it